
Yin Haiwen | Technology Media
the database storage and computing separation architecture is an enduring architecture, the most famous of which is the Oracle RAC cluster. However, the storage and computing separation architecture is slightly different in different databases, the concept of a separate architecture for storage and computing varies in different databases or different application scenarios:
for distributed databases, it is more important to separate the computing function of data from the storage engine, both of which use local resources;
most centralized databases store data in shared storage or from a hardware perspective, and use local resources for computing power, databases can use shared storage by mapping storage resources to local disks.
This article analyzes the features of different databases and scenarios.
1. Based on shared storage
In the Oracle RAC(Real Application Cluster) Cluster, the ASM(Automatic Storage Management) of the GRID component the disks mapped from shared storage are formed into different disk groups in different redundancy modes, and each node of the database is provided with unified storage capacity in the disk group.
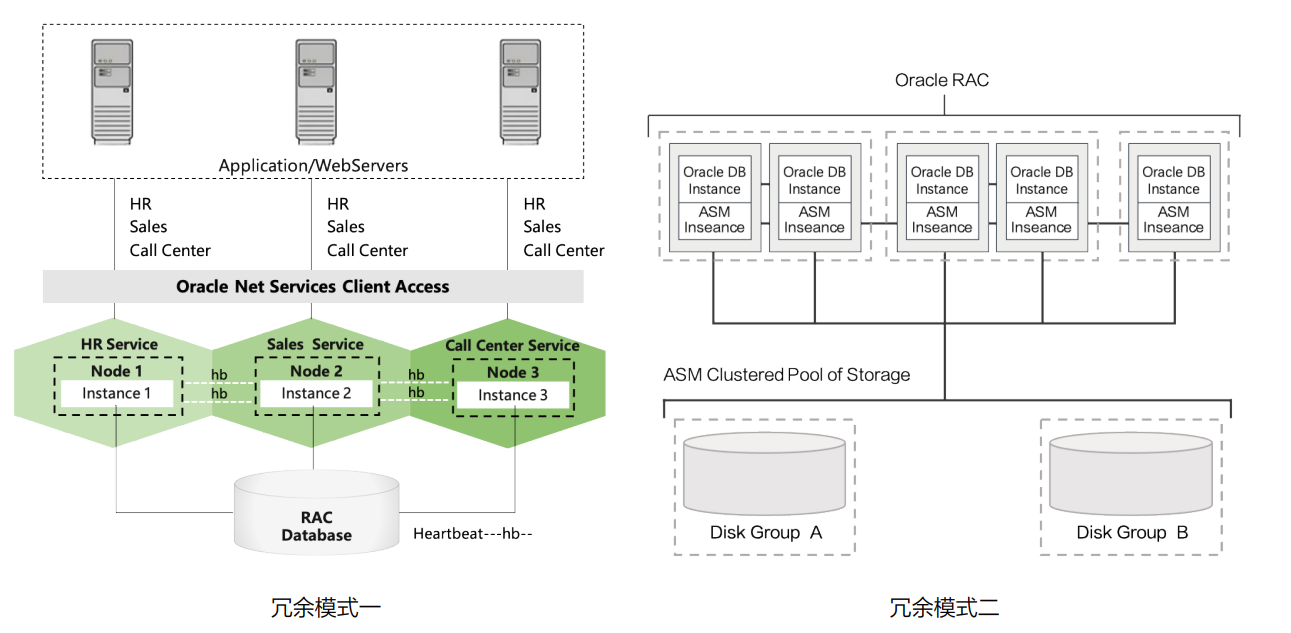
In addition to the redundancy mode, that is, a data copy has several copies in different mapped disks, ASM also stripes the disks in the disk group to improve performance, this maximizes the performance of shared storage. At this time, the maximum performance of Oracle RAC clusters often depends on the I/O performance of shared storage. Similar architectures in domestic databases include KES RAC of Jincang database, DSC of Dameng Database, YAC of Yashan database, apsaradb for PolarDB.
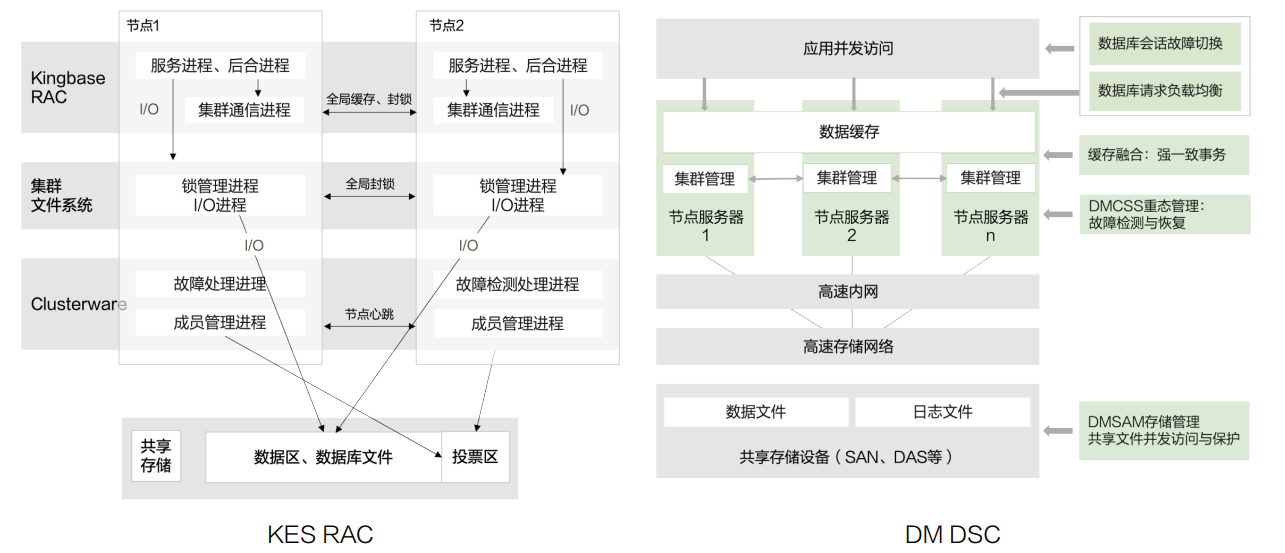
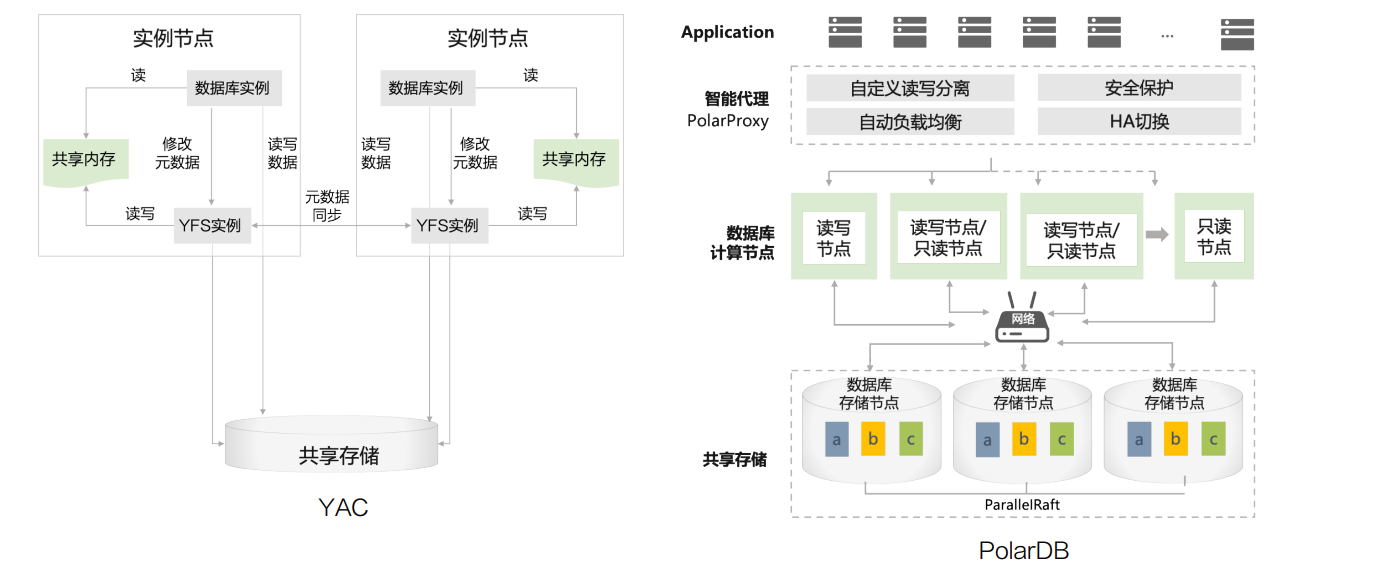
The data inventory separation architecture based on shared storage has many benefits:
in addition to traditional centralized storage, distributed storage can also be used to select appropriate types of shared storage according to different requirements, scenarios, and budgets;
the acquisition of data by nodes does not necessarily interact through networks between nodes, but can be realized by using a more stable and fast dedicated storage network, while reducing the network interaction pressure between database nodes;
after a node exception occurs, the reconfiguration time of the entire cluster is shorter, and the fault judgment method can depend on the storage link in addition to the network, and the data cache loading after node recovery does not need to occupy the synchronization of network nodes; similarly, the increase or decrease of cluster nodes is almost imperceptible.
Of course, this still has disadvantages. For example, the safe and stable operation of databases depends on shared storage. For example, shared storage failures include storage downtime, link transient disconnection, and silent errors, IT will have a disastrous impact on database operation, which also requires that no matter what type of storage you choose, you should be cautious and choose excellent shared storage as much as possible, because databases are the IT infrastructure, the money that should be spent still needs to be spent.
2. Based on the storage engine
many databases have the concept of storage engines. Different storage engines have different characteristics. Take MySQL as an example, there are mainstream MyIASM and InnoDB storage engines, and a relatively niche storage engine -- NDB Cluster. The NDB Cluster itself is a storage-Computing separation architecture. The following architecture diagram is used as an example: mysqld provides database access and computing capabilities, ndb_mgm provides Cluster management and metadata storage, and ndbd provides distributed storage capabilities.
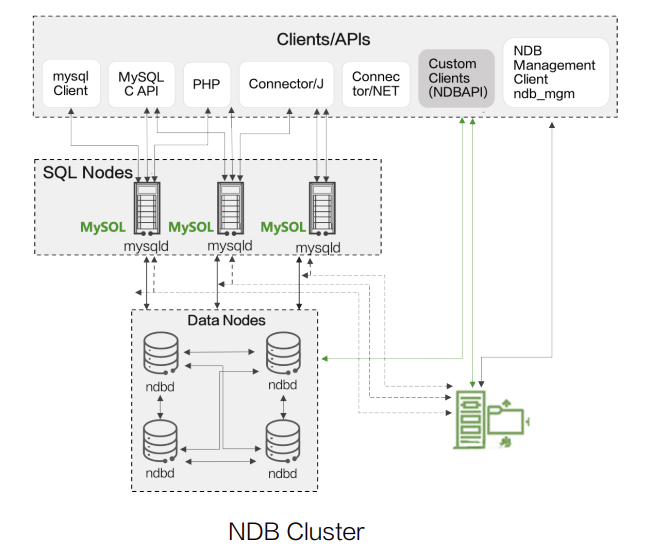
Similar domestic database architectures include TiDB. TiDB Server provides computing capabilities, PD Server stores metadata, and TiKV/TiFlash(Storage) provides distributed Storage capabilities.

Compared with the distributed architecture of the all-in-one computing machine, this architecture does not require business parties to consider the distribution of data on each node.
This type of storage and computing separation architecture directly uses server local resources, and the hardware resources of nodes themselves are not shared at the global level. Theoretically, large scale scale-out can be achieved when the network is robust enough. But this also brings some challenges:
The robustness and data security of a database cluster depend on the high availability of the database itself;
the interaction between database nodes depends heavily on the network, which is unstable. Based on the CAP principle, some things need to be sacrificed, such as latency;
because of the non-shared feature, any node exception requires fault judgment and cluster-related management operations through the network. After recovery, the network needs to be occupied for synchronization.
3. Hybrid architecture
in the upcoming new version of OceanBase, OceanBase databases will support Shared-Nothing (SN) as well as Shared-Storage (SS) mode deployment, which is a shared storage architecture based on general-purpose object storage. Using cloud-native infrastructure can reduce database usage costs to a certain extent.
Each tenant stores a copy of data and logs in the shared object storage, and each tenant caches hotspot data and logs in the local storage of the node. Each primary replica uploads a full baseline data to the object store. The replicas share the baseline data on the object store. All replicas automatically identify the data popularity and only cache hot data locally. Each replica of the tenant is dumped independently, and the dump data is not shared among replicas.
Compared with the storage and computing separation architecture based on shared storage, the SS mode of OceanBase limits the use of object storage, and the local machine also stores logs and some data. The database architecture is relatively complex. In my opinion, the storage performance of most objects is generally not strong, and the performance of databases depends on the local memory and hot data cache, as well as their caching and data calling mechanisms. Of course, this also provides more choices for different demand scenarios.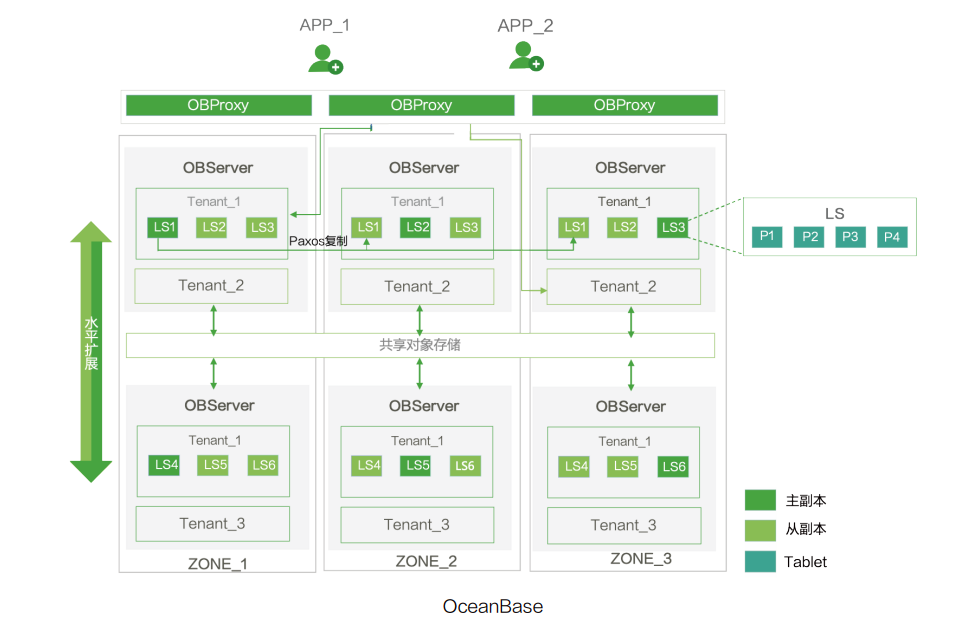
4. Advantages
compared with the database architecture (centralized/distributed) that relies solely on local hardware resources, the emergence of the storage-Computing separation architecture solves the following problems:
the performance and memory capacity of a single CPU are significantly improved, but the capacity of storage disks (especially high-performance disks) that can be carried is limited, storage capacity and performance can be expanded more conveniently through various types of storage and computing separation architectures;
in a distributed architecture, data splitting can reduce or even eliminate the data splitting requirements at the data logic level (that is, data sharding does not need to be considered);
• Computing and storage are decoupled. Failure of computing nodes does not affect database access. Data storage can ensure its security by relying on its high availability;
when using dedicated storage devices, the following additional advantages can be brought:
• More stable, efficient, and secure storage links;
The disk is highly available and can be fully managed;
more stable and efficient I/O performance;
more comprehensive disk performance and hidden danger monitoring, real-time performance degradation, early detection and troubleshooting;
• For high-performance disks, especially NVMe SSDs, there are almost no large-scale application cases in standalone RAID, and dedicated storage has already solved this problem;
• Dedicated storage can be used in multiple database clusters. In a database cluster with a large number of nodes, it saves disks globally and simplifies local disk management.
Of course, dedicated storage devices are not cheap, but are more suitable for enterprise-level applications.
V. Outlook
In many critical task scenarios, a "alien" distributed database architecture for availability and stability has emerged, that is, each node uses the local CPU and memory, however, using the mapping disk of shared storage instead of the local disk to store data not only uses multi-node computing power but also utilizes the high stability of storage. This is a logical architecture that integrates storage and computing but separates physical architecture storage and computing. In this case, if the storage and database can be linked, by directly performing global consistent snapshots or backups of distributed databases through storage, the backup and recovery performance in distributed databases can be greatly improved.
Whether it is dedicated storage (centralized or distributed) or a distributed storage cluster based on storage engines built in various databases, it often has enough CPU and memory. In traditional usage, this part of computing resources is mostly wasted. If you can make full use of this part of computing resources, you can continuously optimize the storage structure, optimize the storage distribution, and automatically layer hot and cold data, adding functions such as filtering data in advance in computing will benefit the overall performance of the database and simplify a large number of optimization management and maintenance operations. With the addition of high-performance and low-latency networks such as RDMA, the storage link bandwidth can be further improved and latency can be reduced, while the storage can be expanded in computing.
VI. Conclusion
this paper summarizes the storage and computing separation architectures of mainstream databases or different scenarios, analyzes the characteristics and advantages of the storage and computing separation architectures, and looks forward to them.
* This article is included in the second issue of the user special issue of "words and numbers"
original link: https://www.oceanclub.org/cn/discuss/info/4173

