
Liang Xiao| deputy general manager, Zhejiang telecom big data center
【 summary]] AI in the era, data has become a key factor to promote social and economic growth and a core factor to promote the development of new productive forces. By building an advanced big data platform and continuously upgrading it, Zhejiang Telecom has built high-quality data services, fully activated the release of data element value, helped enterprises transform their digital intelligence and promoted the development of digital economy.
I, basic information of the project
1, construction Background
zhejiang Telecom is fully responsible for the construction, operation and service of telecommunication network in Zhejiang province. It is an important communication service provider and digital transformation promoter in Zhejiang province, providing communication, cloud computing, and, big data, AI and other comprehensive intelligent services. As the number of users continues to grow, the data scale continues to expand, and large-scale data storage and computing resources become increasingly tight. At the same time, the internal data application of Zhejiang telecom enterprises has a strong demand for efficient data supply. Therefore, the construction of Zhejiang Telecom's new enterprise-level big data platform started.
2, function positioning
(1) response Country " new quality productivity " strategic requirements for data elements
zhejiang Telecom's big data platform is the infrastructure for data aggregation, governance and circulation. It plays an important role in supporting enterprise management, empowering business development and cloud network operation. At the same time, through experience accumulation and technical iteration, an overall solution is formed, " from inside to outside " export, empower the digital transformation construction of government agencies at all levels and large State-owned enterprises, and carry out collaborative innovation in industrial internet, low-altitude economy and other fields to promote the high-quality development of Zhejiang's digital economy.
( 2) promote asset operation and value release of data elements
the country has clearly defined data as the key production factor in the new era, and data has become the national strategic resource. Trusted Data circulation becomes the key to release the value of data elements. As the core data base, the big data platform builds a trusted data circulation platform, a data asset registration platform, data element trading platforms and data application platforms in various industries effectively support data circulation, data capitalization and data value realization.
( 3) help R & D of AI applications to reduce costs and increase efficiency
data-driven has become an important mode for the development of artificial intelligence. Large-scale, high-quality and diversified training data sets have become the key to cutting-edge artificial intelligence applications. The future development of artificial intelligence is " data-centric AI ( Data-centric AI) ". Through the big data platform of Zhejiang Telecom, we have realized efficient management of multi-modal data, built high-quality data sets, and assisted in the innovation of various internal and external artificial intelligence applications, anti-communication fraud and other fields are widely used.
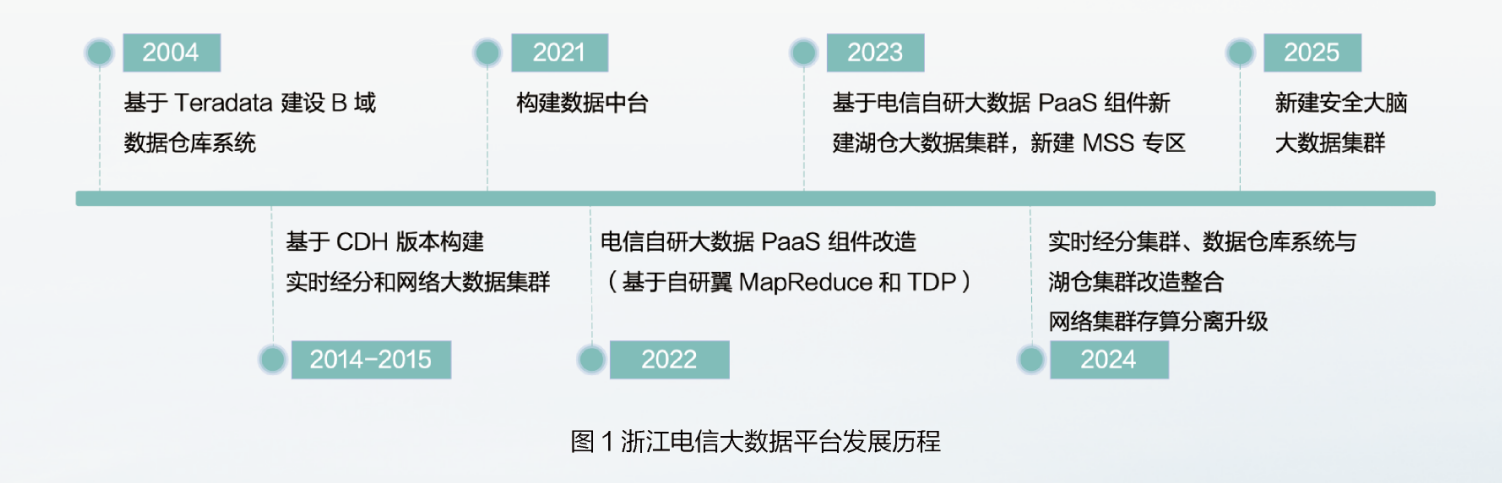
3, development history
zhejiang telecom big data platform from 2005 it started construction in. Up to now, it has basically completed the construction of the big data base platform, data mid-end and data asset management platform, and has built a complete data infrastructure system.
Among them, the proportion of self-developed components of the big data base is 65.3%, consisting of two clusters, distributed in Jinhua and Shaoxing. Jinhua cluster mainly carries the unified aggregation, production and processing, and data application services of network data. Shaoxing is a sub-cluster that uses the integrated architecture of Lake warehouse. Its core components include: IceBerg, Flink, Doris, Clickhouse and so on, mainly carrying the unified aggregation of business data, production and processing, and data application services. The overall data storage scale of the big data platform exceeds 30PB, the cluster size exceeds 1700 nodes, each day carrying a variety of data analysis tasks 10 ten thousand, daily average data collection 300TB, peak traffic 10GB/s.
II, construction and evolution of big data base platform
As the core cornerstone of the entire big data platform, the big data base platform is constantly upgraded and optimized based on business needs and innovative technologies.
1, new business challenges
zhejiang Telecom initially adopted Commercial DB2 database, successfully supporting hundreds TB high-level data analysis has excellent interactive query capability. However, as the data scale continues to grow, the computing and storage resources of the database need to be expanded synchronously, resulting in a rapid increase in data storage and computing costs. In addition, the limit on the number of nodes in a single cluster also restricts the scalability of the system and cannot support the data storage and computing requirements caused by rapid data growth.
With Hadoop with its good scalability and low hardware costs, Zhejiang Telecom's big data platform has been promoted DB2 step by step Hadoop evolution, built a close 400 node size Hadoop cluster. Hadoop the computing and storage integration mode is adopted, and the three-copy mechanism is adopted to ensure data reliability. But 4G to 5G with the transition of the times and the explosive increase of data, the problem of this architecture has gradually become prominent.
( 1) low resource utilization: Big data servers purchased by Zhejiang Telecom, in order to balance capacity and performance requirements, generally choose balanced 12 disk-based servers with low storage density and unbalanced computing and storage utilization. In an existing network cluster, when storage resources are about to run out, the average utilization rate of computing resources is less 20%, wasted investment. In addition, the multi-replica data protection policy causes the available capacity to be only bare capacity. 1/3, the disk utilization is extremely low, and a large number of hardware devices need to be purchased to meet the data storage requirements. To 7PB for example, you need to purchase 300 more than one server, more than one investment 2000 more than ten thousand, occupying nearly 40 cabinets, the annual operation and maintenance cost exceeds 200 ten thousand, greatly increasing the cost of digital transformation of enterprises.
( 2) performance bottleneck: Hadoop the metadata management node of the cluster data storage layer is in the active/standby mode, and requests for adding, deleting, checking, and modifying data files must be managed through the metadata management node. When the file data exceeds 1.5 after 100 million, the performance is close 50% the attenuation of the data limits the expansion of the data scale. In the case of large concurrency, the metadata management node may even crash. In order to solve the bottleneck problem of metadata management, business departments have to split the business, create multiple sets of metadata management nodes, and control the data size of each set of metadata management node within a certain range, however, multiple metadata management nodes incur additional O & M costs.
( 3) reliability risk: integrated storage and calculation Hadoop the construction solution uses a single cluster. 3 replica mode, exceeding 2 if multiple nodes fail at the same time, there is a risk of data loss. During data recovery IO and internal IO unseparated, data refactoring IO it also needs to occupy business network resources, which affects business performance. In addition, Hadoop it is a pure software product, which lacks monitoring and prediction mechanism for hardware. In the case of dozens of hard disk failures every month, the hard disk needs to be replaced frequently to ensure the stability of the system.
Zhejiang big data center initially focused on structured data analysis applications. With the rapid development of artificial intelligence technology, efficient governance of unstructured data such as text, video, and audio has become a hot spot, traditional technology architectures can no longer meet the data requirements of artificial intelligence applications. In this context, big data urgently needs to integrate artificial intelligence technology to provide underlying support for intelligent applications and create high-quality datasets to empower the development of artificial intelligence applications. Therefore, for future upgrades, we need to focus on the following key factors:
( 1) unified management of multi-source heterogeneous data: supports unified management of structured, semi-structured, and unstructured data, and supports fusion analysis of multi-source heterogeneous data.
( 2) flexible and highly scalable architecture design: supports flexible and fast horizontal expansion to meet the needs of massive data storage. At the same time, it is highly reliable in distribution to avoid data loss caused by hardware failures.
( 3) native AI technology embedding: based on AI technology implements data optimization management, including intelligent index construction, Automatic hierarchical storage, and automatic fault prediction, greatly improving data management efficiency.
2, architecture upgrade and optimization
the data base of Zhejiang Telecom's big data platform mainly includes Shaoxing economic cluster and Jinhua network cluster, among which Jinhua network cluster mainly carries network data aggregation and analysis tasks. This time, combined with the above questions, comprehensive consideration AI the data base and platform components of the network cluster have been upgraded. Specifically:
( 1) the storage and computing separation architecture uses a professional distributed storage system that integrates software and hardware at the storage layer. It has a fully symmetric architecture and supports four-level reliability mechanisms such as hard disks, nodes, systems, and solutions, meet the high reliability requirements of Zhejiang Telecom. Through high-density storage and EC14 +2 erasure code technology to change the proportion of replica resources from 33.3% drop 12.5%.
( 2) the soft cache technology is used to optimize the interactive performance between the storage layer and the computing layer so that the computing nodes CPU significantly improved utilization and streaming throughput 20 ten thousand / seconds to support real-time location services.
( 3) based on China Telecom's self-developed big data PaaS component set (wing MapReduce, short " wing MR”) upgrade the big data base to replace CDH and adapt to professional storage OceanStor Pacific, implementation PaaS components are self-controllable.
( 4) push Cross IDC collaborative Computing integration, complete full stack localization (server /OS /PaaS), strengthen the platform unity and autonomy and controllability.
The upgraded architecture is shown in the following figure.
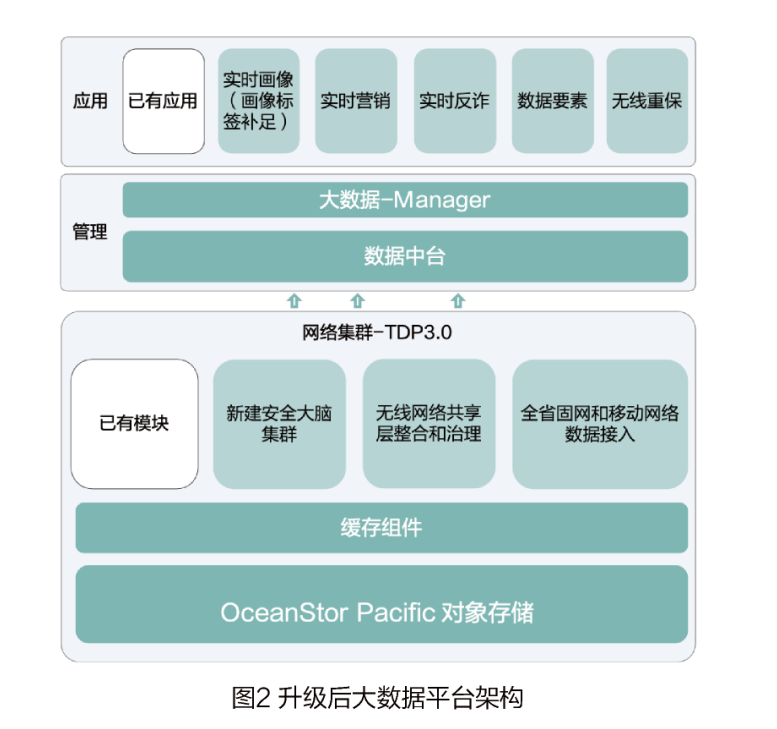
Self-developed network clusters PaaS platform, total number of nodes 663 objects 173 node.
Resource usage: computing resources ( Memory: 75.14TB, CPU: 14362Core), the usage is approximately 77%; Object storage resources 12.33PB, the usage is approximately 57.3%.
Data Production and Management: gathers data related to the fixed network and mobile network, as well as data related to the cooperation between the group and the outside world, and provides unified data aggregation, data warehouse production and processing, and data application services. Currently, the amount of data gathered per day exceeds 300TB, the number of tasks processed per day exceeds 22000.
After the upgrade, the entire cluster runs smoothly. Currently, the fourth phase of the upgrade is about to be carried out to expand the underlying distributed storage based on the storage and computing separation architecture to carry network information security-related services.
3, benefits after upgrade
( 1) effective resource optimization: native HDFS semantics, which separates big data storage and computing, forms an innovative architecture of storage and computing separation that expands on demand, allowing you to expand storage and computing resources more flexibly. The storage layer uses a large proportion of commercial levels. EC(Erasure code) replaces multi-copy data protection technology, greatly improving storage space utilization, significantly reducing hardware procurement costs, data center space occupation, and energy consumption costs. Currently, overall storage saves resources. 7.07PB, reduce hardware and operating costs 500 ten thousand yuan, with further use, the results will be more prominent; Computing resources are based on China Telecom's self-developed big data PaaS component set (wing MR) transform and upgrade to the storage and computing separation architecture. Currently, the average performance of tasks is improved by more 30%.
( 2) performance and cost optimization: hardware-accelerated EC according to the actual calculation, compared with open-source components EC the technical performance is more stable and meets the requirements of large-scale data storage. At the same time, the throughput performance is improved compared with that of general-purpose servers while maintaining data reliability. 3 more than times. 5G compared with the times 4G in the era, the data volume is probably 3 double growth, data storage costs are very big challenges. Adopt the new memory-Computing separation architecture and EC technology, the number of equipment from before the transformation 1120 after the downstage is transformed 734 set, reduce 34.4%, save about 1200 ten thousand, of which the equipment cost is reduced by about 700 wan / year, O & M costs reduced by approximately 500 wan / year.
( 3) thoroughly resolve metadata bottlenecks and single fault domains: in the storage and computing separation architecture, the storage layer adopts a fully distributed metadata management architecture. All metadata is scattered to nodes, and all metadata processing and query are also distributed to all nodes. This improves the efficiency of business access and simplifies management. Business departments do not need to split businesses and manage multiple metadata management nodes. In addition, compared with servers, professional distributed storage features high availability of hard disk, node, and system-level data, and supports multi-fault domain design. After this upgrade, the network cluster is divided 3 fault domains, allowed in extreme cases 6 node failures ensure reliable data availability.
( 4) native HDFS, " old and New " coexistence: built on the big data storage layer HDFS nano Tube function -- metadata Gateway, which has been deployed through na Guan Xian network HDFS, implements a unified entry for data access at the application layer, and supports writing data to the storage layer first. HDFS. Select write based on configuration HDFS. Load balancing write HDFS A variety of write policies have truly achieved smooth business evolution without perception.
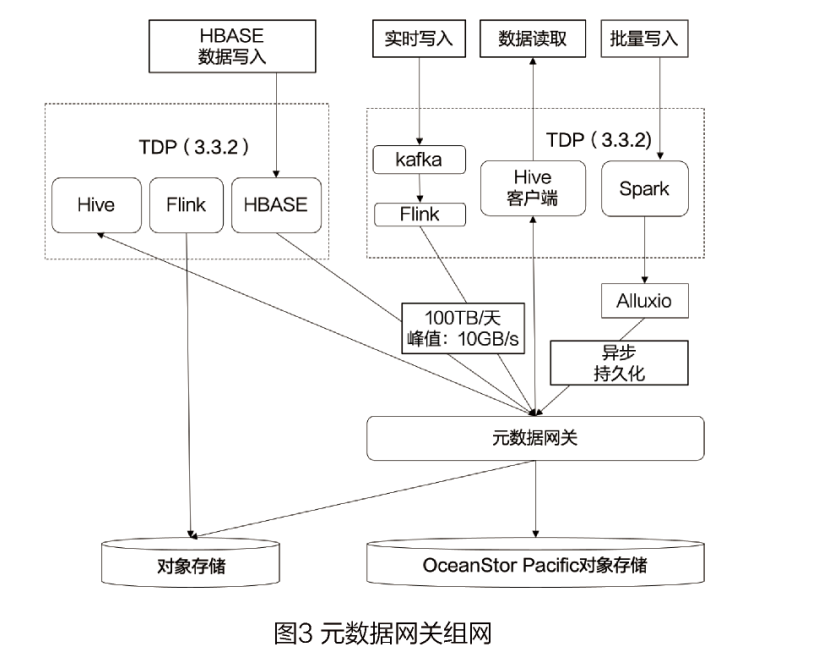
( 5) unified data into the lake: for AI lay the foundation for high-quality data. Through technologies such as intelligent hierarchical storage and unified metadata management, data can be efficiently entered into the lake, and global data can be retrieved and moved across regions. This improves data management efficiency, and enables intelligent data governance and real-time analysis. AI business requirements such as training and reasoning.
4, business innovation and practice based on big data platform

( 1) business capability system
Up to now, Zhejiang telecom big data center has built and operated a total of network big data platform (Jinhua) and Jingfen big data platform (Shaoxing) 1700 the remaining nodes form three core modules: data base platform, data governance platform, and data application platform:
• data Base Platform: Based on China Telecom's self-developed big data PaaS component set (wing MR) as the core, including IceBerg, Doris, Spark, Flink, ClickHouse and other core big data components that support the collection, storage, and computing of massive amounts of data. At the same time, they are equipped with self-developed component management tools for component O & M and resource scheduling optimization.
• data governance platform: Based on China Telecom's Xinghai digital intelligence mid-end, the integration of data development, data governance and data asset operation is realized, standardized data management processes are constructed, and enterprise-level global data asset catalog is created, effectively manage and efficiently supply data assets. At the same time, it also supports data labeling, model training, model reasoning, model evaluation and other functions to achieve AI model development and application.
• data Application Platform: It integrates and analyzes basic data to build rich data application services, and is widely used in scenarios such as anti-communication fraud, crowd insight, accurate publicity, and precise marketing, good results are obtained and the full release of data value is realized.
( 2) business innovation practices
• intelligent Anti-fraud service
Based on abundant data resources and artificial intelligence technologies, it creates intelligent anti-fraud services, providing intelligent call protection, intelligent internet access protection, intelligent risk device identification, and intelligent risk. APP various capabilities such as identification, intelligent risk website identification, intelligent fraud warning, etc.; A complete anti-communication fraud management system has been built, including: AI active early warning measures such as outbound calls, SMS messages, and flash messages, as well as remediation and disposal capabilities such as online filtering, illegal shutdown, and calling interception. 2024 in 2002, Zhejiang telecom big data center gave full play to its advantages in data resources and technology and achieved remarkable results in the field of risk prevention and control. The intelligent analysis platform provides more accurate data services throughout the year. 1000 for example, help identify and block multiple high-risk events, and directly avoid and recover economic losses. 2000 ten thousand yuan.
• precise location service
based on accurate location service, real-time population statistics, Regional flow heat, electronic fence and other data are developed. Combined with SMS capabilities, accurate access is realized. It is widely used in disease prevention, crowd counseling, early warning of flow of people, disaster warning and other social security application scenarios, especially in ensuring the safety of major events, precise location services play an important role. Currently, the average daily call volume of the precise location service reaches 30 ten thousand times, send text messages every year 2.5 hundreds of millions of times, serving enterprise customers 500.
• portrait service
based on data analysis, build personal, family, and corporate portraits to support more than a thousand precise marketing activities each year, provide users with precise recommend products and services, and improve the conversion rate of activities. 5-10 it helps improve the service quality and value contribution of existing customers and makes important contributions to the high-quality development of enterprises.
5, create the next generation AI-Ready big Data Platform
In the next phase, Zhejiang big data center will focus on the following 5 evolution in the general direction, building a secure and intelligent big data platform for the next generation, further enabling data value mining and efficient circulation of data elements, including:
full Stack localization: promote the localization of key middleware and application software based on the upward extension of the current localization Foundation;
green data base: the green, full-flash, and high-density data base is introduced to efficiently store the explosive growth of unstructured data for a long time;
digital Intelligence mid-end: pass AI technology implements intelligent data classification and classification, intelligent metadata completion, and intelligent data quality problem discovery and repair, significantly improving data governance efficiency and data quality, and continuously providing high-quality data feedback based on the platform. AI training system to form data governance and AI apply a virtuous circle of mutual promotion;
AI O & M: explore Building AI the driven intelligent scheduling system deeply optimizes the use of computing resources, comprehensively improves the cluster operation efficiency, builds intelligent diagnosis capabilities, and improves fault autonomy and timeliness;
application enhancement: focus on the construction of data element circulation platform, realize the safe and reliable circulation of data, promote the efficient integration and wide application of data, and promote the full release of data value.
III, conclusion
After years of practice and verification, the Computing separation architecture has become the core path for the evolution of Zhejiang Telecom's big data platform. Facing the new era of digital intelligence, we will " data elements ×AI driver " as a strategic pivot, upgrade to a new generation based on the separation architecture of storage and computing AI the data lake platform is the core base for the digital and intelligent transformation of enterprises. This platform will continue to provide high-quality data fuel for AI applications, promote the transformation of data assets to productivity, and help enterprises achieve a leap-forward development from digitalization to intelligence. By building a secure, reliable, intelligent and efficient big data infrastructure, we are committed to injecting new momentum into the digital transformation of thousands of industries, serving the national economy and people's livelihood with data intelligence, build a solid digital cornerstone for high-quality economic development.
* this article is included in the user special issue of "words and numbers" 2 period
original link: https://www.oceanclub.org/cn/discuss/info/3773

