
Build high quality AI data infrastructure to promote efficient circulation and utilization of data resources
zhang Lianzhu| China Software Evaluation Center director, Data Governance evaluation office
[Abstract]] in recent years, big model technology has made continuous breakthroughs, and the investment in large-scale and high-quality training data has played a key role in it."Data-centric artificial intelligence" is pushed to a new stage. With the digital and intelligent transformation of thousands of industries and hundreds of industries moving towards deep water areas, new key applications such as AI, HPC and big data are accelerating their integration into the production decision-making system of enterprises, in particular, the generation AI wave opens up the Pandora's box, activating the potential of massive unstructured data such as videos, voice, text, and pictures. In this context, we will establish and improve the technological development path for the efficient circulation and utilization of data resources in the AI field, and build a domestic and high-performance AI data infrastructure base, building data and AI two-way empowerment are becoming more and more important.
I, china three challenges in efficient circulation and utilization of data resources in AI
china is speeding up the construction of a new data infrastructure based on trusted data space for efficient circulation and utilization of data resources, promoting the construction of high-quality data sets and accelerating their implementation."Artificial Intelligence" action. However, promoting the efficient circulation and utilization of data resources in the AI field still faces difficult challenges such as imperfect institutional mechanisms, imperfect technical systems, and high security risks.
1. Institutional mechanism to be improved
currently, due to the limited scale of open-source datasets, insufficient data processing capabilities, copyright issues, disconnection from actual business scenarios, lack of executable construction standards, the construction process and continuous supply of high-quality data sets in our country are severely restricted due to factors such as "emphasizing construction rather than operation" and the lack of continuous optimization and maintenance mechanism. At the same time, different industries, there is a lack of effective organizational guidance and open collaboration mechanisms between different regions and different types of subjects, and there is a lack of effective trust mechanisms among all parties involved in data circulation. In addition, the boundary of data ownership is unclear, problems such as access policy, property right system, transaction rules, income distribution, safety supervision system and other supporting basic systems are not perfect, which to some extent affect the efficient circulation and utilization of data resources in AI field.
2. Technical system to be optimized
on the one hand, storage performance bottlenecks restrict data circulation efficiency. At present, the data volume in China continues to break through in the scenarios of autonomous driving, medical imaging, industrial Internet, scientific computing, etc. The data types are evolving rapidly from structured to unstructured and multi-modal fusion, this poses a severe test to the heterogeneous, multi-protocol support, and hybrid load processing capabilities of storage systems. At the same time, large model training data collection takes a long time in scenarios such as high-frequency financial transactions, online recommendation, real-time industrial control, and interactive scientific research, and consumes a lot of data preprocessing resources, traditional media such as HDD are limited by high latency and low IOPS, which cannot meet the performance requirements of AI and real-time analysis scenarios.
On the other hand, the data development and utilization capabilities are insufficient, the data service capability of global visual manageable availability needs to be improved.
1)AI's exponential demand for computing power, network and data has aggravated the bottleneck of traditional facilities, the rigid architecture of traditional systems is difficult to adapt to the efficient circulation and utilization of data resources and the dynamic changes of AI workloads;
2) the massive, multi-source, heterogeneous and dynamic data environment puts forward new requirements for storage facilities and data management capabilities, the scale and quality of data supply cannot meet the needs of high-quality development and utilization and AI development;
3) the data quality is uneven, and the phenomenon of inaccurate, incomplete, inconsistent and untimely data is common. The circulation and utilization based on low-quality data is not only ineffective, but also harmful, seriously reduce the quality of data products and services;
4) data standards and specifications are different. Most enterprises lack unified metadata standards, data formats, coding standards, interface standards, etc., which make it difficult to understand data from different sources and systems, interoperability and integration form a "data Island", which hinders the efficient circulation and utilization of data and the realization of data capitalization;
5) lack of effective life cycle management, most enterprises lack unified management strategies and tools for data collection, storage, processing, use, destruction and other links, data redundancy, invalid data accumulation not only wastes resources, but also increases management complexity and security risks.
Big model upgrade and iteration need to build an efficient data management platform based on high-quality data sets and supporting data labeling and data processing to generate and manage massive amounts of data.
3. Security risks still exist
the significant expansion of data circulation scope, sharp increase in frequency and diversification of participants have significantly increased risks such as data leakage, abuse, tampering and cross-border security.
On the one hand, the risk of data circulation is high. Traditional data security focuses on static storage and database boundary protection. In the era of artificial intelligence, data lifecycle security is required, and continuous security during data circulation is emphasized, this greatly increases the complexity and implementation difficulty of protection. Data is at risk of leakage in all aspects such as collection, storage, processing and transmission. Personal sensitive information such as identity information and transaction records are easily coveted by criminals.
On the other hand, the situation of cross-border flow supervision is severe. Data has become a new link to the global economy. Countries have accelerated the formulation of policies on data sovereignty, data localization, personal information protection, etc. General Data Protection Regulations ( GDPR) and California Consumer Privacy Act (CCPA) and other international regulations and increasingly strict domestic supervision have put forward higher requirements for compliance.
In addition, traditional storage facilities have obvious deficiencies in reliability, security and manageability. Traditional storage architectures lack hardware-level protection, and security policies are difficult to unify, so they cannot cope with the current large-scale data circulation scenarios. Moreover, traditional storage media are vulnerable to physical damage, electromagnetic interference, and hacker attacks, it is difficult to guarantee the security and reliability of data. Data security and privacy protection capabilities need to be strengthened.
II, feasible technical path for efficient circulation and utilization of data resources in AI field
Through technological architecture innovation, based on distributed storage, build high-performance, high-reliability, and intelligent management capabilities the "1 2 3 N" AI data infrastructure system ensures efficient collaboration among data streams, computing power resources, and model assets, enabling rapid deployment and iterative AI capabilities across the industry, build a feasible technical path for efficient circulation and utilization of data resources and AI bidirectional empowerment.
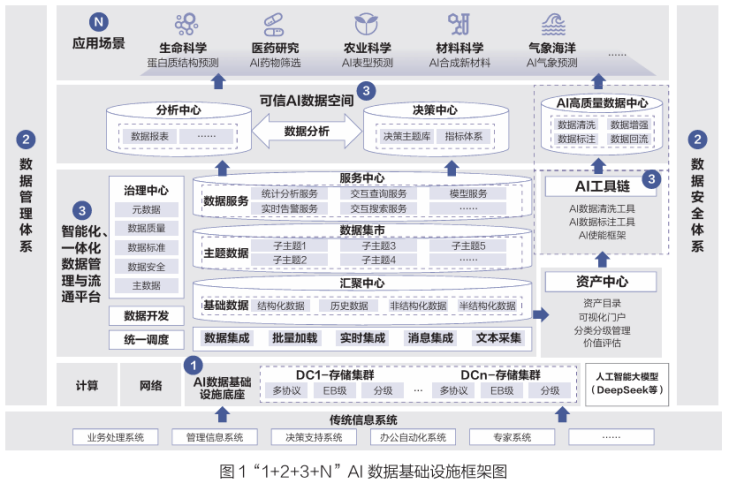
1 2 3 N AI Data Infrastructure framework, where:
"1" refers to building an AI data infrastructure base with high-performance all-flash distributed storage on the basis of the national data infrastructure;
"2" means that on the basis of effectively implementing the existing national system, we will continue to improve the supporting standards and specifications for data circulation and utilization, and improve the two control systems of data management and data security;
"3" means to improve the data service capability of "global visual manageable availability", promote the high-quality supply and efficient circulation and utilization of data, reduce the cost and threshold of social usage, and build intelligence, integrated AI data Lake, AI tool chain and AI trusted data space;
"N" refers to N scenarios to empower the real economy, promote high-quality social development, create new advantages in international competition, and continuously deepen the efficient circulation and utilization of data resources in the AI field.
The "1 2 3 N" AI data infrastructure is a framework suitable for AI applications proposed by China under the background of promoting the development of artificial intelligence and the marketization of data elements, it aims to build a comprehensive data infrastructure environment that supports AI big model training, application and industrial development based on the construction of national data infrastructure.
1. Break through the limitations of traditional data infrastructure, build a unified data space through advanced storage technologies, and accelerate the construction of AI data Lake
create a new domestic and high-performance model the data infrastructure base of AI data Lake needs to integrate the four core capabilities of hardware autonomy, software ecology, data scheduling and green energy conservation to build a collaborative system covering computing power, storage and network. The new AI data Lake is a data storage and management platform specially designed for AI applications. It can store and process multi-modal data (text, image, voice, etc.) in a unified manner, and supports large-scale data processing and intelligent analysis. The unified data space is built through advanced storage technology. The full Flash distributed storage supports EB-level data storage with extremely low energy consumption per unit, meeting the massive demands of medical images, media-funded videos, educational and scientific research scenarios. Driven by the accelerated implementation of the AI data infrastructure, the commercially available industry-advanced all-flash distributed storage supports up to 61.44 TB of large-capacity SSDs, the SSD capacity is 2 to 3 times higher than that of a single HDD disk. AI data Lake and advanced storage media are reconstructing the AI data infrastructure paradigm-from "computing power first" to "data driven", the storage system has been upgraded from an auxiliary carrier to a strategic pillar that determines the performance of the AI model.
2. Build an intelligent and integrated data management and circulation platform to improve the data service capability of "global visibility, manageability, and availability"
build an intelligent and integrated data management and circulation platform, aiming to realize the full life cycle management of data resources through technology integration and process optimization, and significantly improve globally visible, manageable, and available data service capabilities. This process not only involves the innovation of technical architecture, but also emphasizes organizational collaboration and value creation, injecting new momentum into decision support, business innovation and public services.
The core of the intelligent and integrated platform lies in integrating advanced technologies, opening up data barriers and forming a unified data governance system:
1) in the data collection layer, IoT, sensors, and API interface to achieve real-time aggregation of multi-source heterogeneous data, ensuring data comprehensiveness and timeliness;
2) at the data processing layer, big data analysis, artificial intelligence and ML technologies are used to clean, integrate and extract raw data and convert it into structured and analyticable information assets;
3) establish a standardized data catalog and metadata management mechanism in the data management layer to support data classification, classification, and permission control to ensure data security and compliance;
4) at the data application layer, visual tools and API services are provided to empower business scenarios, such as intelligent decision-making, risk warning, and personalized services. Its intelligent features are reflected in the platform's autonomous optimization capabilities, for example, the algorithm model is used to dynamically adjust the data processing process, or the prediction analysis is used to predict data requirements, reducing manual intervention and improving response efficiency.
The global visual, manageable, and available capabilities reflect the platform value:
1) global visualization, building a unified data view, through unified data space, incremental metadata real-time synchronization, geographic information system (GIS) and other technologies, to achieve cross-departmental, cross-system data panoramic display;
2) it can be managed and controlled, strengthen the data governance framework, and implement full-process monitoring, including setting up data quality assessment indicators to ensure accuracy, and preventing data leakage risks through encryption and access control technologies, and establish an audit tracking mechanism to clarify the main body of data responsibility;
3) it is easy to use, optimizes the data service interface, lowers the use threshold, and supports flexible data query, analysis, and sharing functions, such as using natural language processing technology, non-technical personnel can easily obtain the required information, thus accelerating business innovation and optimizing public services.
3. Create a trusted AI data space to accelerate the large-scale circulation and utilization of data resources
implement the national data Bureau's trusted data space development action plan (2024-2028) to build a trusted AI data space to ensure that data providers, data users, data service providers, trusted data sources, such as space operators, share data resources in a trusted environment, implement ubiquitous access to the lake, trusted data, and AI availability, and improve the high-quality supply of AI datasets, build a multi-subject value co-creation model, build an efficient data resource circulation mechanism and a sustainable operation model, and promote the integration and innovation of trusted data spaces and large models.
Around data"Supply, flow, use well and ensure safety" to achieve the following basic measures:
1) in the aspect of data supply from Zhirong, it can provide a number of innovative technologies such as engineering Corpus cleaning, intelligent corpus labeling and integrated data supply to ensure the supply of high-quality corpus;
2) in terms of smart drive data flow, it can follow the international standard architecture of data space and pass "4W2H" (Where, Who, When, What, How to, How Many) the model's data control strategy, OS UCON-based operating system kernel-level application control and confidential computing technology, cracking the "uncontrollable circulation" in the circulation of data elements ", key challenges of" Transmission insecurity;
3) in terms of good use of Zhilian data, it can provide three AI technologies: data modeling, data intelligence and data vectorization to accelerate the realization of data value and empower the evolution of business to intelligent innovation;
4) in terms of data security protection, full-link security protection capabilities should be provided in environmental security, data security, model security, content security, and security operations, build multiple linkage digital security protection measures of "Network + storage + calculation.
4. Promote the efficient circulation and utilization of AI-driven data resources and deepen scenario empowerment
build the integrated system of "collection number-governance number-use number" drives data from resource to asset through three-dimensional linkage of technology base, mechanism innovation and scene adaptation.
1) in terms of strengthening the data base, we should build an AI Ready storage hub, build a storage center, break down industry data barriers, and release high-value industry data through scale aggregation, supports AI transition from general intelligence to professional intelligence.
2) in terms of innovative circulation mechanism, hierarchical and controllable data space should be established, and three levels of trusted data space of enterprises, industries and cities should be established. Through data View, environment and service standardization, promote the double cycle of on-site and off-site transactions.
3) in terms of deepening scenario empowerment, focus on key areas such as medical treatment, industry and government affairs to promote the efficient circulation and utilization of AI-driven data resources. For example, in the medical field, AI model distillation technology deploys the 32B parameter expert model to county-level hospitals, with the diagnostic accuracy approaching the top three levels and reducing the cost of cross-provincial medical treatment; For example, in the industrial field, the AI energy consumption optimization algorithm dynamically schedules production loads, improving energy efficiency by 20%-30% in industrial scenarios. For example, in the field of government affairs, the government data platform integrates cross-department and cross-level government data, supports cross-region collaboration of "efficiently doing one thing" and speeds up decision response by more than 40%.
III. Conclusion
in during the "15th Five-Year Plan" period, artificial intelligence will become the core engine to promote high-quality development. Efficient circulation and utilization of data resources is the key to releasing the value of data elements. It is necessary to take "system as the basis, technology as the path, the scenario is core, which gradually forms a closed loop of data resources" available, flowing, using well, and ensuring security.
Based on the system, establish and improve policies and measures for efficient circulation and utilization of data resources at the national level. Effectively implement the existing system, and speed up the formulation of supporting standards and specifications for circulation and utilization; Actively build a system of multi-subject collaborative governance, and clarify the rights and responsibilities of multi-subject; Accelerate the establishment of data property rights definition, market transactions, rights Distribution and interest protection system; Supplement and perfect adaptation data infrastructure policies and standards for AI applications.
Technology-based, large-scale layout of all-flash distributed storage facilities to accelerate build an AI data Lake to build an efficient and intelligent data infrastructure. Build an efficient, secure, and low-carbon All-Flash distributed data storage base, accelerate the construction of AI data lakes in various industries and regions, strengthen the construction of high-quality data sets, and realize global data management, visualization, "Available", build a trusted circulation environment, promote trusted data space technology, improve the underlying anti-attack capability of storage devices, and strengthen the security capability of software and hardware.
Take the scene as the core, expand and deepen based on AI's data resource development and utilization scenarios improve the application breadth and depth of AI infrastructure. Empower the digital transformation of vertical industries such as intelligent manufacturing, intelligent medical care, intelligent city and financial science and technology, consolidate the independent, controllable and leading position of AI infrastructure, enhance the national scientific and technological competitiveness, and drive the prosperity of AI ecology, guarantee the sustainable development of society.
* This article is included in the 3rd issue of the user special issue of "words and numbers"

